39.4 Running Microsimulation and Interpreting the Results
Open the Healthcare tutorial example tree, MicrosimulationCancerModel - Distributions.trex, which incorporates both trackers and distributions resampled per trial for patient characteristics. If a model is built using Microsimulation, then it needs to be run using specific Analysis, not the usual Expected Value analysis (for example Rankings or CEA graph).
Once model calculations require trackers in order to calculate correctly, the model should be analyzed only with Microsimulation. Expected value analyses (i.e., roll back, Markov cohort analysis) will ignore the trackers and will yield incorrect results.
If you have trackers and/or trial-level distributions in your model, TreeAge will warn you prior to running any analyses that do not include Microsimulation.
To run a microsimulation:
-
Select the root node.
-
Choose Analysis > Monte Carlo Simulation > Trials (Microsimulation)... OR
-
Click the single die icon in the Analysis layout tool bar.
-
Enter 10,000 trials in the Monte Carlo Simulation dialog.
-
We want the Average values returned for the trial set, so leave the Average button selected. Select Begin.
-
By default the stabilize strategies checkbox is checked, so the patients will take similar paths through similar strategies, as in the image below.
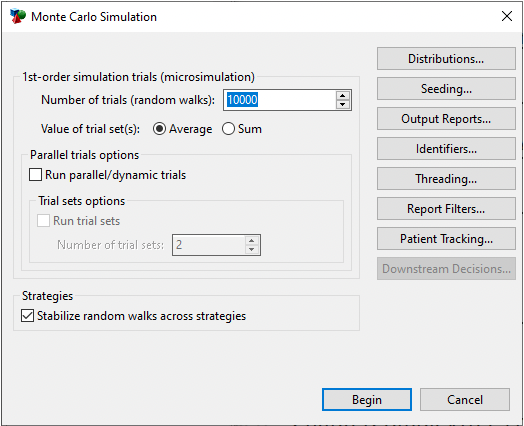
Stabilize random walks across strategies: When checked (default), the same random number sequence is used for all strategies, so patients will take similar paths through similar strategies. When unchecked, strategies use different random number sequences, so patient pathways will immediately deviate among strategies. The default is off.
After the simulation is complete, you will be presented with the Monte Carlo Dashboard with the results from the simulation.
Microsimulation performs the following steps:
-
A single trial enters the model.
-
The trial is assigned characteristics (from either the bootstrap or distribution).
-
The trial runs through the model via a random walk.
-
Data - payoffs and trackers - are updated as the trial runs.
-
When the trial completes its run, the final data for payoffs and trackers are stored.
-
Steps 1-5 are repeated for all subsequent trials.
-
The data is collected and aggregated into mean values to represent the Expected Values for each strategy.
-
Conclusions can be drawn from a comparison of the strategy EVs.
The Monte Carlo Dashboard provides a direct view into the underlying results as well as access to additional graphs and reports that help you interpret the results.

The Dashboard has the following information:
-
Analysis Information: This includes the analysis type, number of iterations (in this case trials), model calculation method and WTP.
-
Summary of Results Table: This shows the average NMB, cost and effectiveness for each strategy. The virtical line indicates the mean value with the shading around it representing the prediction intervals around the means.
-
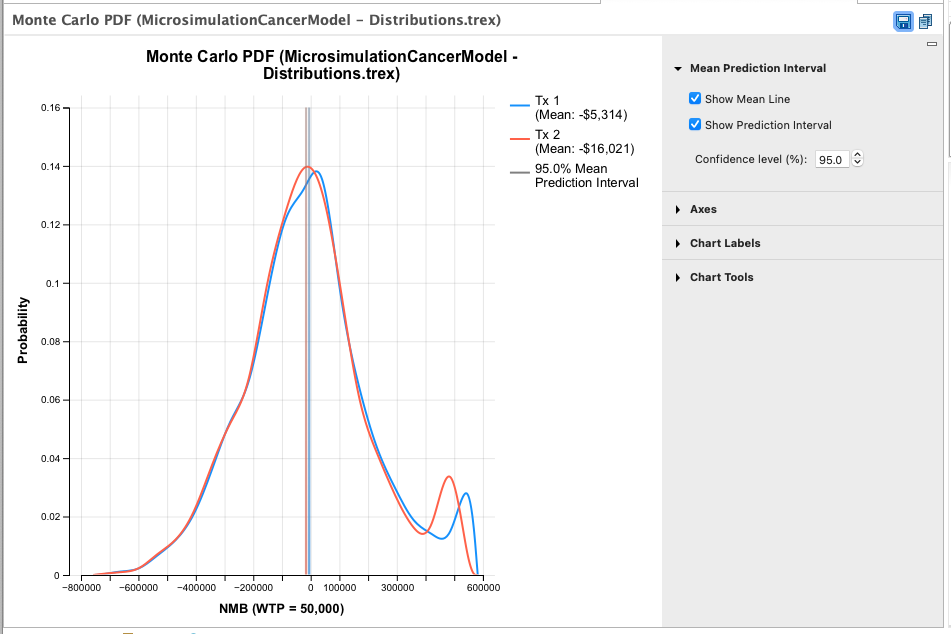
Probability Distributions of CE Outputs Graphs: A probability distribution trend line for each strategy showing the mean and variance among model calculations. The graph default uses NMB, but tabs are available to switch to Cost or Effectiveness. The vertical lines and shading represent the mean values and the prediction interval around those means. Links to open these Dashboard Graphs are in Data Reports.
-
Quick links to commonly-used outputs: Click on the icon to open the associated graph or report.
-
Full list of data reports and graphs: To the right of the Dashboard is a full list of links to all reports. The individual reports are described below.
Data Reports
The first link in the Data Reports is the Dashboard Graph which lets you open and edit the Probability Distribution graphs in the dashboard. The usual graph editing tools are available on the right-hand side.
Statistics report provides the statistics for each payoff, tracker and distribution in the model. This report includes controls to the right to change the percentages for the Prediction Interval mean statistics and to hide/show different data values.
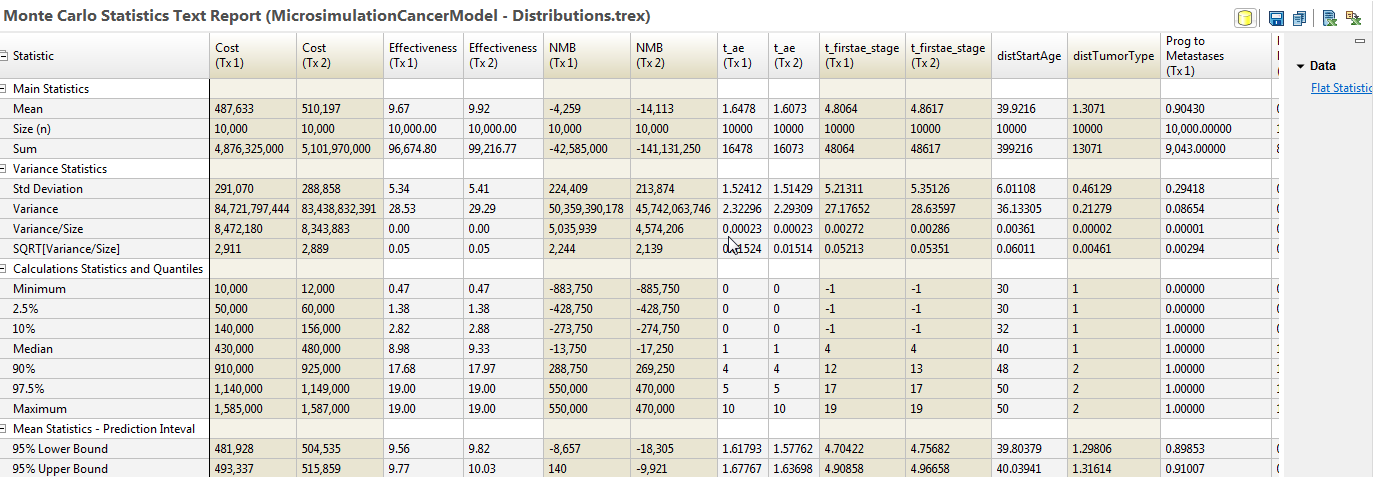
For more information on prediction intervals, refer to section Robustness of Simulation Results.
All Data report shows each iteration's (i.e. each trial's) payoffs, trackers and distribution values reported on a separate line. These are the individual values which are aggregated to give the Expected Value calculations. In most cases, the individual trial data is not valuable except as a contribution to the overall estimate of expected value.
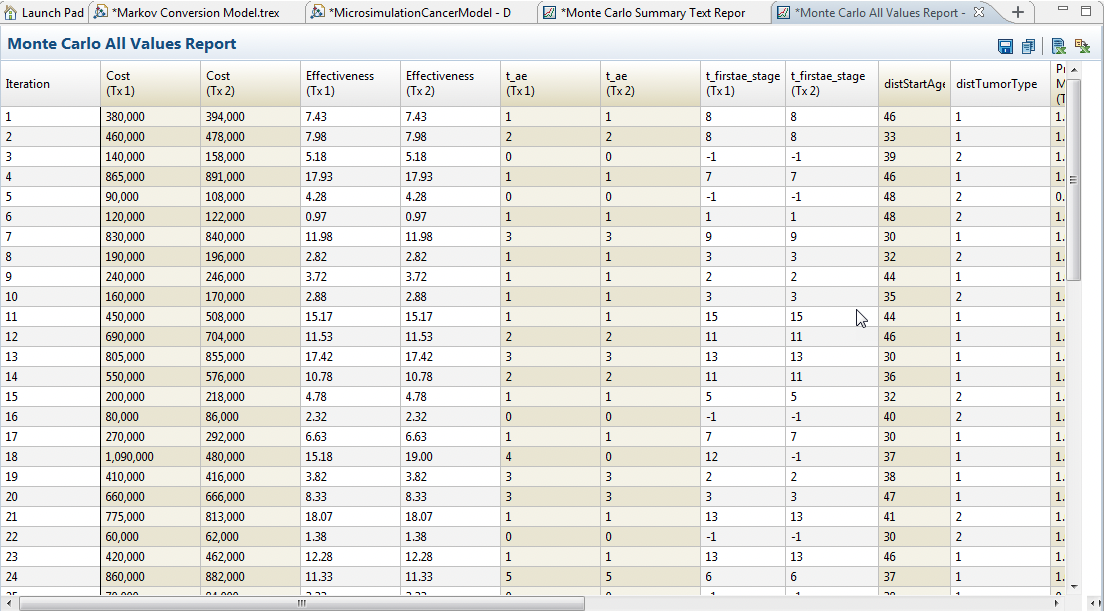
The Export All Data to Excel/CSV link exports the same data from the All Data report to a CSV file easily opened in Excel.
The ability to generate multiple Custom Scattterplot for model outputs and strategies.
CE Outputs
CE Rankings shows the usual rankings report generated from the Expected Values from the microsimulation.

Additional outputs like histograms are also available to see variance among model runs. These histograms are highlighted in the Probabilistic Sensitivity Analysis on CE Models. However, there is a significant difference between the histograms from microsimulation versus those from PSA.
-
Microsimulation - histograms are based on individual model runs, so signficant variance is expected.
-
PSA - histograms are based on full model calculations, so less variance is expected.
